
(This post builds on the query creation guidelines found in Part 1, Advice to Aspiring SQL Masters, which sets out a formula for building basic SELECT queries. Examples are from Microsoft’s Northwind database, which you can create using the instructions on the linked page)
Once you’ve mastered building basic SELECT queries, including filtering with the WHERE clause, and sorting with ORDER BY, you might start asking yourself more complex questions about your data. (Remember: A query in plain English is simply a question. A SQL query is a question we ask the database!)
More complex questions like:
–How many orders did each customer make last year?
–Who is our newest employee? Our most senior employee?
–How much gross revenue did each product in the Fashion Accessories category generate in May?
Where this sort of query will differ from a basic SELECT is, we can’t get the answer by looking at individual rows! For example, if I want to see each individual order made in a certain year, I can do that with a basic SELECT:
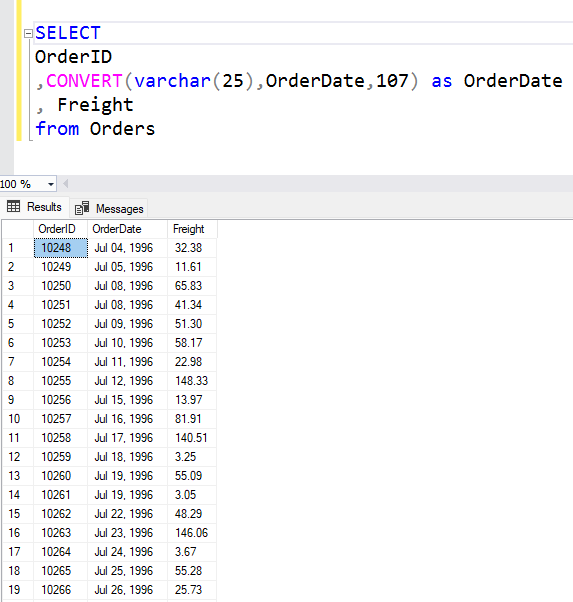
Note: One row in the results here represents a set of field value from one row in the table (This changes slightly when you’re doing joins, given that you may be getting results from 2 tables that are one-to-many related. In those cases, one row in the “one” side of the relationship can end up being repeated many times given the data in the “many” table).
When we start asking questions that require aggregates and grouping, one row in the table won’t equal one row in the results anymore. We’re asking the query engine to process multiple rows to produce one result. For example, “how many orders did Customer X make last year?” is simply a counting process: “How many rows in the Orders table have Customer X’s id on them?”
Aggregates can exist on their own, so let’s start there:
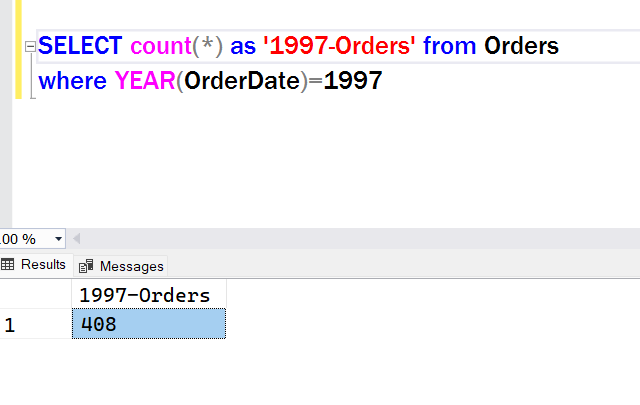
Even in this case, the query engine is doing a count of rows. But what if we want to see the number of orders for each client? Then we need to add grouping, since we’re asking the query engine to give us totals for specific subset(s) of data:
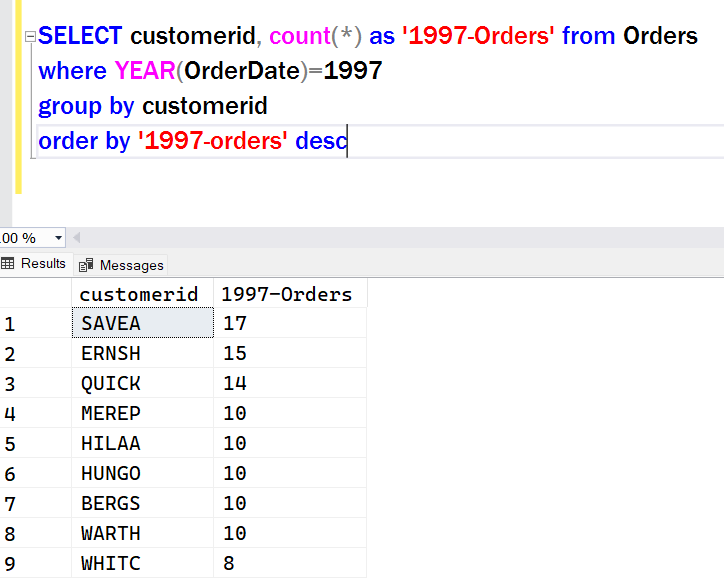
While this query performs as expected, there’s often an expectation that we can simply add columns to the SELECT list. The rules change a little here though, because of the aggregating and grouping that’s being done behind the scenes. Let’s say our requirement asks for the company name instead of just the ID:
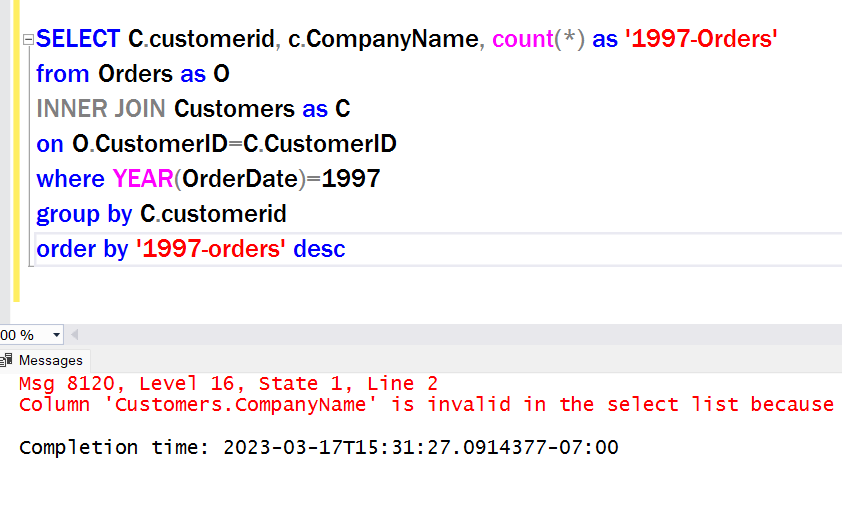
While our software tool (SSMS) doesn’t word wrap the error line, here’s the full text: Column ‘Customers.CompanyName’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.”
So here’s the rule to remember when grouping:
Every column in the SELECT list must either be
(A) an aggregate
or
(B) part of the GROUP BY statement.
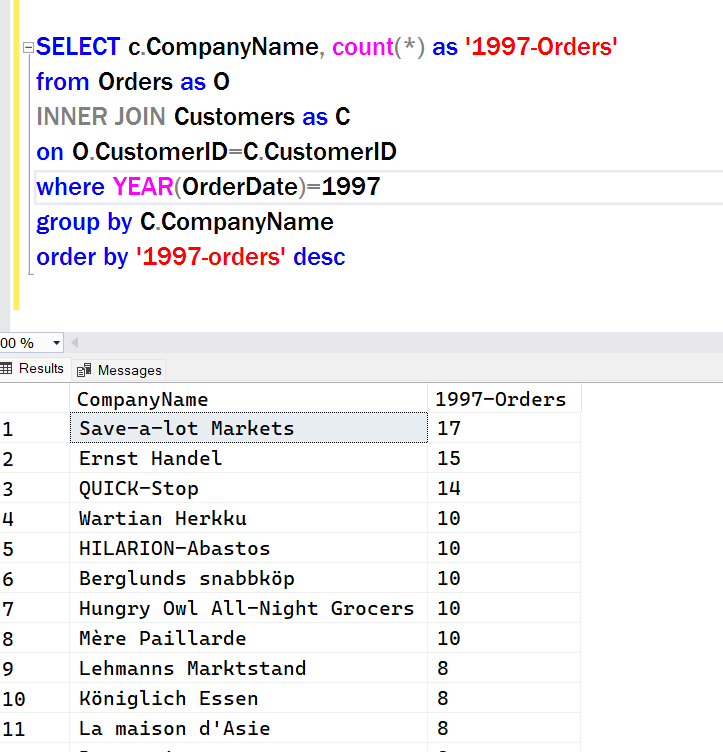
Easy enough to have the query group on CompanyName instead of CustomerID. But what if we want to see both?
This one is relatively simple, since each Customer has a unique Company Name. This lets us know that adding the 2nd grouped field won’t produce more groups.
(For a contrasting example, think about having, say, CustomerID and OrderDate as the grouped fields– This would produce a new group for each combination of Customer and OrderDate. Probably not that helpful!)
But for this query, we just add both fields to the GROUP BY statement:
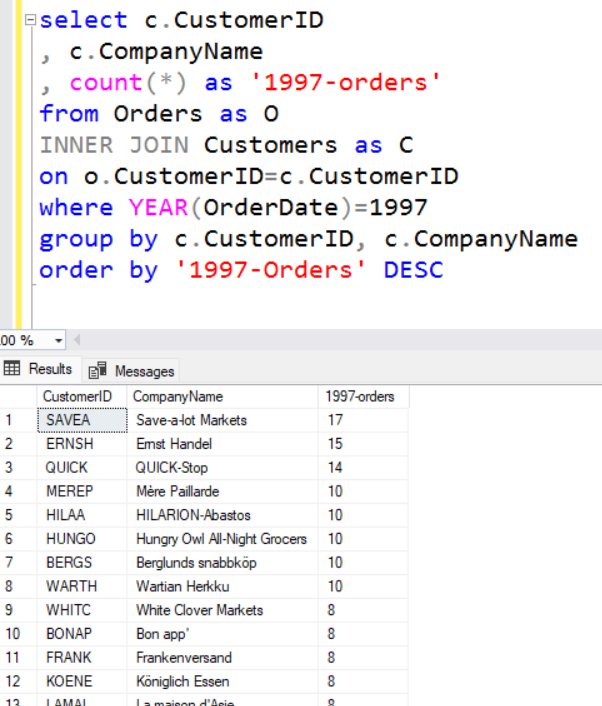
To summarize, here’s what to remember when starting to create queries with GROUP BY
- Each unique combination of values across ALL your grouped fields produces a new group in the result set
- Most often, you will minimize the number of columns in a GROUP BY query relative to a “simple” SELECT
- Every field in a GROUP BY query must either be an aggregate or part of the GROUP BY clause
Happy coding!
No Comments Yet